Percepts are used to improve agent's future behavior, as well
as serving as the basis for current actions.
An agent can learn by observing its own decision-making process.
Learning may occur by simple memorization or may involve higher-level
processes such as analogy.
We will focus on inductive learning: constructing a function
called a hypothesis from a set of input/output examples.
The hypothesis represents the agent's current knowledge about how to
respond in any given situation.
Most learning agents can be described in terms
of four components:
The Performance System selects actions in response to percepts.
The Critic monitors the performance of the agent and generates
feedback that can be used to improve performance.
The Learning Algorithm uses feedback to update the internal
hypothesis used by the Performance System.
The Experiment Generator uses the updated hypothesis to generate new
problems for the system to explore in order to maximize its rate of learning.
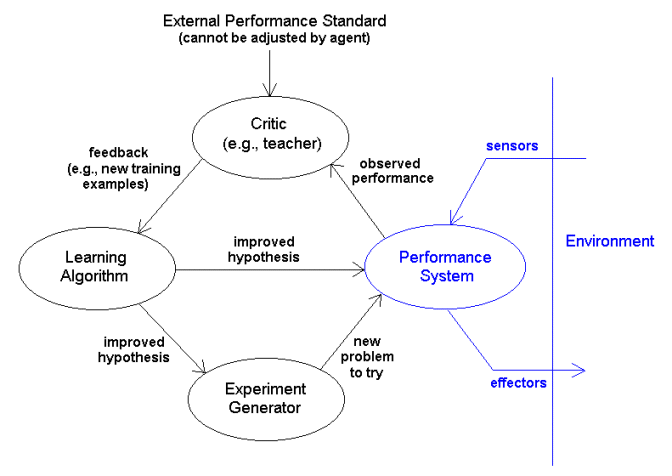
So far, our agent designs have focused on just the Performance System.
Performance standard should be external, so that the agent must adjust
its performance to fit the standard, not the other way around.
The Experiment Generator forces the agent to explore new situations.
Otherwise, the agent would keep doing whatever actions it has determined are
the best so far, even though there may be better untried choices.
The choice of learning algorithm depends strongly on the choice of
representation for the knowledge to be learned (i.e. the
hypothesis), and vice versa.
Learner is given a series of training examples <x1,
f (x1)>,
<x2, f (x2)>, . . .
Learner returns a hypothesis h that approximates the target
function f.
Suppose we have the training examples below:
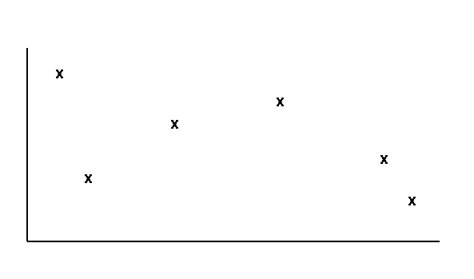
The following hypotheses are possible:
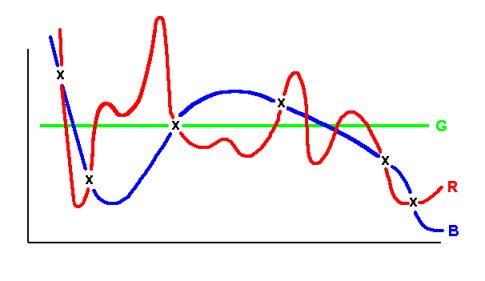
Hypothesis G is too simple — it passes through only one
point.
Hypotheses R and B approximate the training examples
equally well, but differ in how they assign values to unknown inputs. Since
f is unknown, no reason to prefer B over R.
In general, if two hypotheses approximate f equally well, no
a priori reason to prefer one over the other.
Learning algorithms that do exhibit a preference exhibit inductive
bias.
Example: one common type of inductive bias is called Occam's
Razor: Prefer the simplest hypothesis that fits the data. This bias
would prefer hypothesis B above.
Without some type of inductive bias, generalization would be
impossible. The agent would be unable to decide how to respond to situations
it has never seen before.
Hard question: How do we know when the learned function is good
enough?
We want the agent to perform well in novel situations, but we won't
know what those situations are until they happen.
Use the following methodology to evaluate hypotheses' ability
to generalize:
Collect a large set of examples
Divide examples into disjoint training and testing sets
Use learning algorithm on training examples to generate hypothesis
h
Measure the portion of testing examples that are correctly predicted
by h
Repeat steps 1-4 for different sizes and mixtures of training and
testing sets
|
Critical assumption: Distribution of training examples is identical to
distribution of testing examples.
This makes theoretical results easier to obtain, but is not always
valid in practice.
It is best to use freshly-generated examples each time in step
5, rather than a different mixture of the same examples, but this is
often difficult to do in practice.
Performance System uses h to choose next move
at each step in the game.
Critic generates new training examples <b,
Vtrain(b)> based on current hypothesis and
observed performance of agent.
Learning Algorithm updates feature weights according
to training examples provided by Critic, using LMS algorithm, and outputs
new hypothesis h.
Experiment Generator always proposes same problem
(i.e. initial checkers board state), but in principle could propose
other board states to practice on.
Assumes that the ideal target function V is representable within a
hypothesis space of linear, continuously-valued, six-coefficient, polynomial
functions.
Performs hill-climbing search (actually, gradient descent) in
hypothesis space.