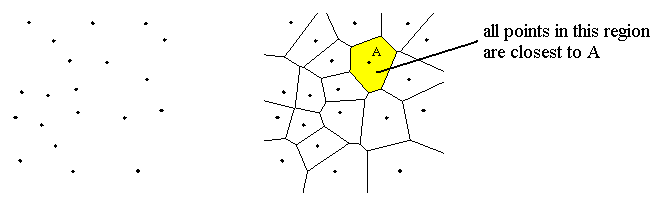
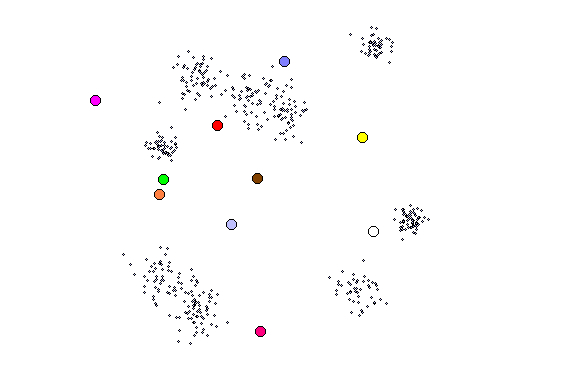
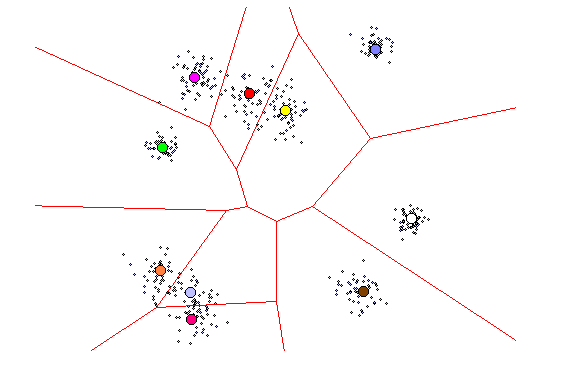
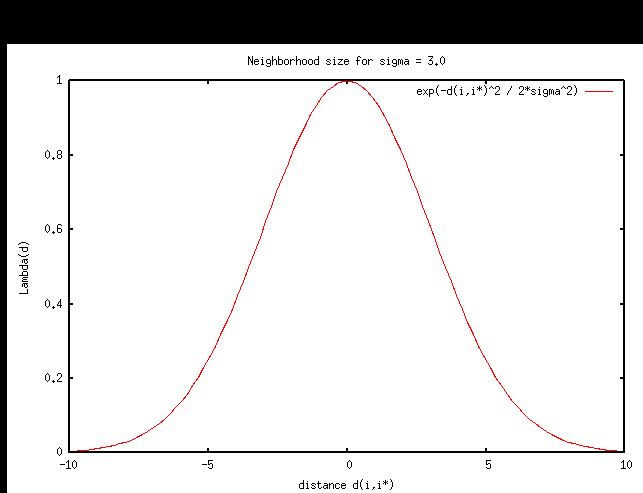
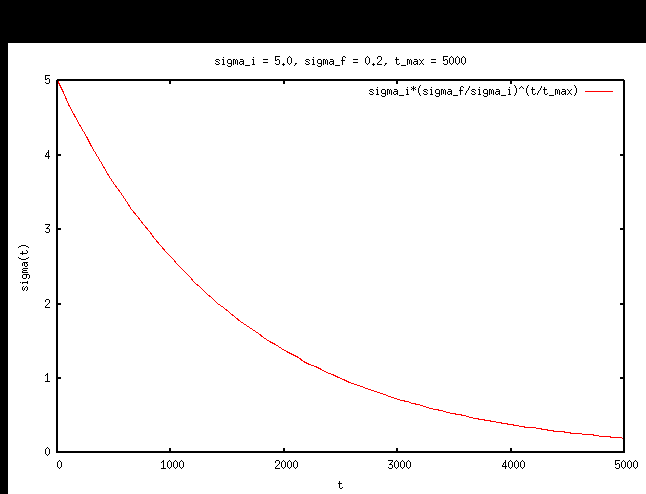
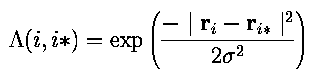Goal is to cluster or categorize the input data.
Categories must be discovered by the network itself from regularities in the input data (data is unlabelled).
Can be used for data encoding and compression by replacing each data vector by the index number of its category (vector quantization).
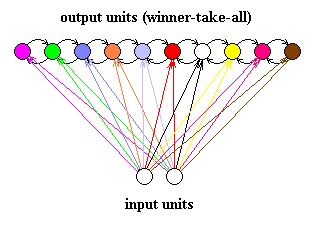
Network architecture:
- Single layer of weights.
- Input units fully connected to output units.
- Lateral inhibitory connections between units in output layer.
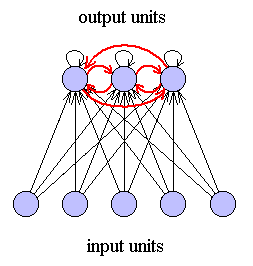
Output units compete to classify input patterns.
Only one output unit fires at a time: the one with the largest incoming activation.
Winner-take-all process can be implemented by simply picking the unit with the highest output or through lateral inhibitory connections.
Problems with "grandmother cell" representations:
- Dedicated output unit required for each category.
- Not robust to degradation or failure. If one output unit fails, entire category is lost.
- No way to represent hierarchical knowledge.
Simple Competitive Learning Algorithm
Initialize network weights to small random values.
Choose a pattern x from the dataset.
Apply pattern to input layer and determine winning output unit i*.
|x − wi*| < |x − wi | (for all i)
where wi is the weight vector for output unit i.
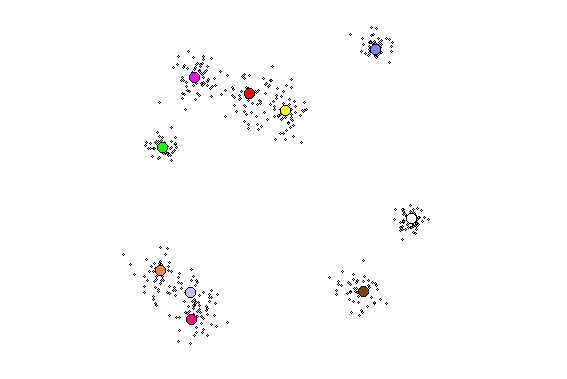
Update the weights of the winning unit i* only.
Δwj,i* = η × ( xj − wj,i* )
wj,i*new = wj,i*old + Δwj,i*
where xj is the jth component of input vector x
and wj,i* is the weight from input unit j to winning output unit i*.Go to step 2 and repeat for the next input pattern until output weights stabilize.