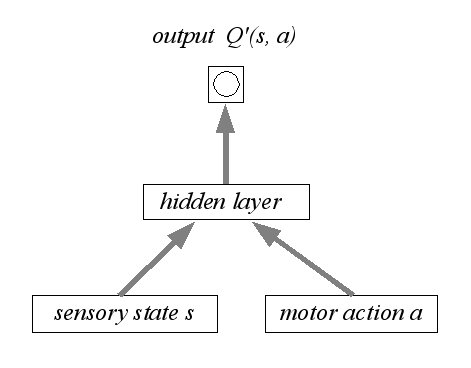
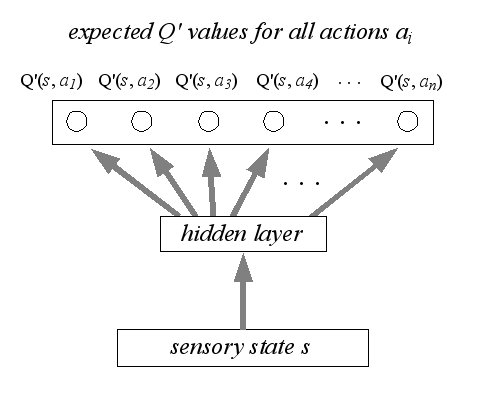
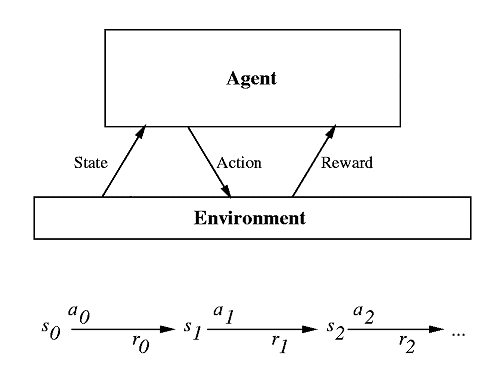
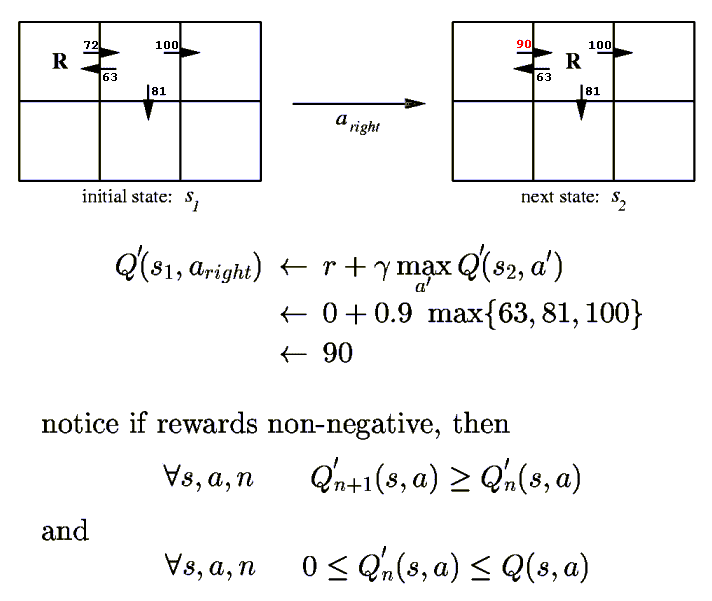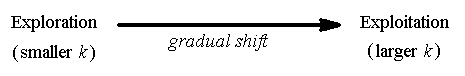Agent can perceive a set S of distinct states.
Agent can choose from a set A of actions to perform.
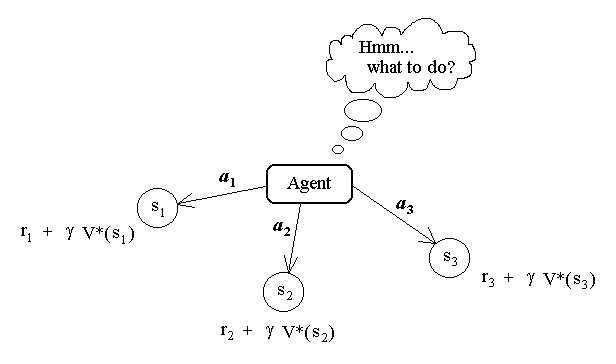
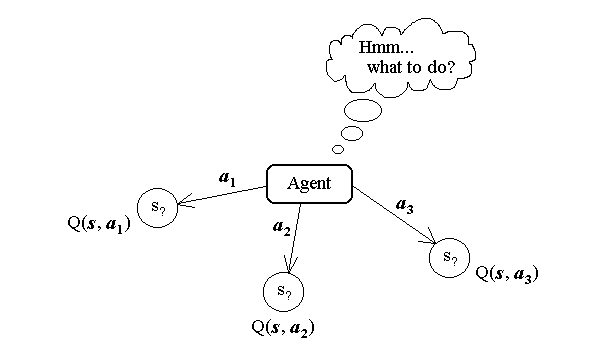
Agent must learn a target function π : S -> A that maps from states to optimal actions.
Supervised training is not possible, because the optimal actions π(s) are unknown.
Only a sequence of immediate reward values is available to the agent.
Rewards that happen later are less important than rewards that happen sooner.
Goal: Learn to choose actions that maximize the cumulative reward over time
r0 + γ r1 + γ 2 r2 + γ 3 r3 + . . .
where the discount factor 0 < γ < 1 determines the relative value of immediate vs. delayed rewards
If γ = 0, delayed rewards are irrelevant.
If γ = 1, immediate and delayed rewards are equally important.
Future rewards are discounted exponentially by their delay.
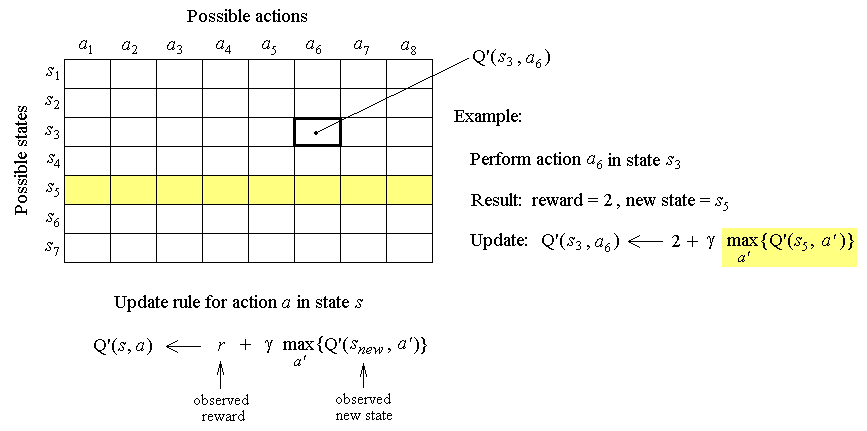
Problem of credit assignment: how to determine which of the agent's actions are responsible for eventual rewards?
Agent faces a tradeoff between exploration of unknown states and actions (to gain new information) and exploitation of learned states and actions (to maximize its cumulative reward).
Environment described by a reward function r and a state transition function δ:
rt = r (st , at) is the reward received for performing action at in state st
st+1 = δ (st , at) is the new state resulting from performing action at in state st
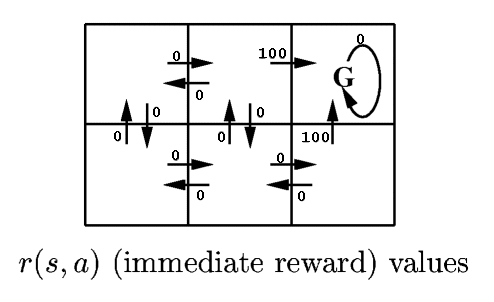
r and δ may be nondeterministic or unknown to the agent (i.e., agent may be unable to predict the results of its actions).
The discounted cumulative reward Vπ for a particular policy π specifies the total reward achievable by the agent by following the policy from any given starting state:
Vπ(st) = rt + γ rt+1 + γ 2 rt+2 + γ 3 rt+3 + . . .
Example: if the current state is s, Va(s) = 81, and Vb(s) = 99, then the agent would be better off following policy b, because it would achieve a higher reward in the long run.
The optimal policy π* is the one that achieves the greatest cumulative reward for all states.
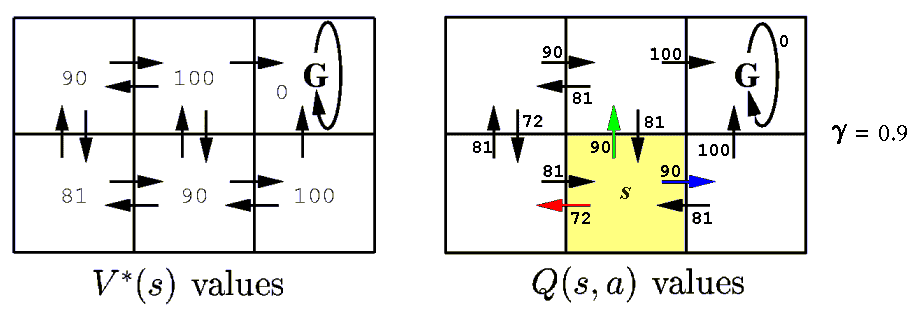
V*(s) is the value function of the optimal policy.
V*(s) gives the maximum possible cumulative reward that the agent can obtain by starting in state s.
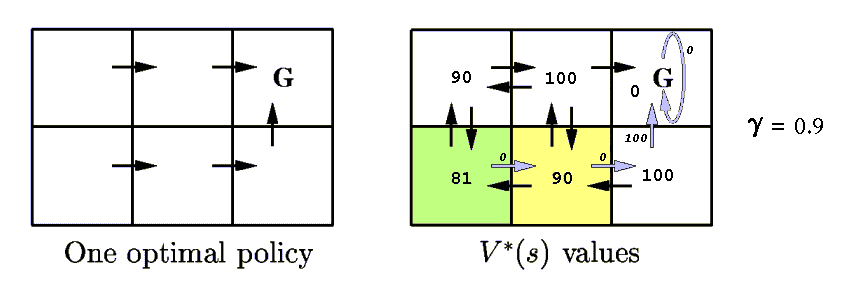
V*(syellow) = 0 + γ 100 + γ 2 0 + γ 3 0 + . . . = 90
V*(sgreen) = 0 + γ 0 + γ 2 100 + γ 3 0 + . . . = 81